Self-describing IPFS content identifiers and their limits
2022 Nov 01
See all posts
Self-describing IPFS content identifiers and their limits
The vision and capabilities of IPFS have, to say the least, blown me away. A peer-hosted decentralized storage layer is something that captures the attention of idealists all around. So, it was exciting when I got the opportunity to hack on the kubo library, which is the golang implementation of IPFS.
The Problem
At CovalentHQ we extract, process, and index blockchain data to expose it as a unified API. The centralized version of this is already available, and we're currently creating a decentralized network which can do the same thing. This network will manufacture several network artifacts (e.g. block specimens) which need to be stored somewhere. One option for storage is AWS S3, or a self-hosted database layer. But what's the point of a decentralized network if the storage layer itself is centralized? Due to being decentralized and battle-tested, we chose IPFS to build our storage layer on.
Content Identifiers
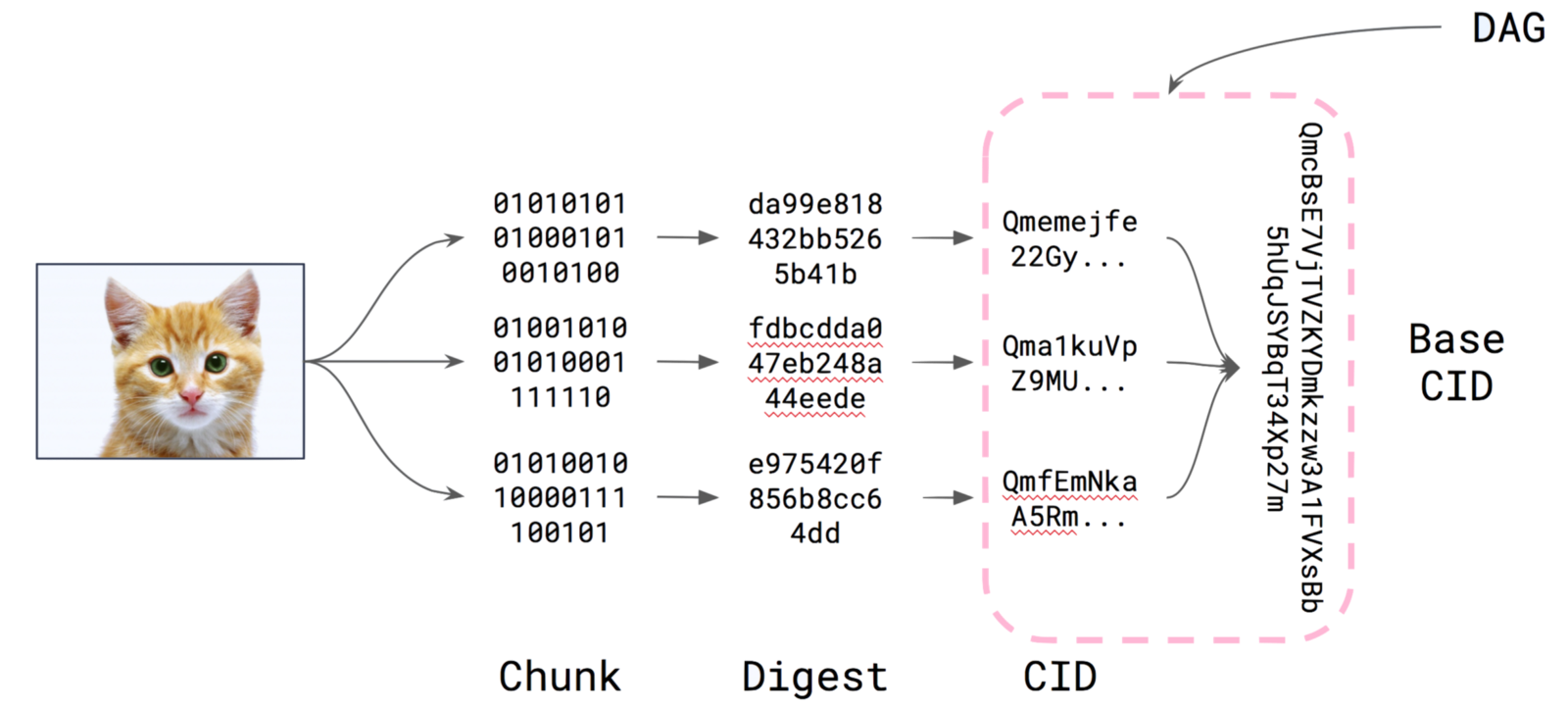
In IPFS, you can "add" content, on which IPFS returns an identifier called content identifier or CID. Now, CID is a self-describing format, which means a CID contains, within itself, the algorithms applied to the content to arrive at that particular CID. In other words, the CID encapsulates sufficient information within itself to figure out the hash which represents the content passed by the user.
Merkle DAGs
When you "add" content to IPFS, IPFS would split that into various "chunks" which are then laid out in a merkle DAG structure, the root of which is THE content identifier. Splitting the data into chunks allows reusability and better distribution of the data, which because crucial as the content size grows.
Pinning Services
Pinning services are hosted services that allow you to "pin" content to IFPS (which means the pinned content won't be GC'ed and deleted from the IPFS node). It ensures data persistence and availability which is needed whether we use pinning services like pinata, or have the network self-host the data (via IPFS). These pinning services essentially use IPFS nodes behind-the-scenes, served through web-apps and APIs.
Now, you would imagine that when we pin the data in any pinning service, the CID generated should be the same. But alas! That wasn't the case for web3.storage and pinata, each of which generated different CIDs.
Why was that?
Well, the CID ultimately generated depends on the algorithm used (and encoded) within the CID, yes. But it also depends on the structure of merkle DAG generated.
➜ ls -lh big-image.jpg
-rw-r--r-- 1 sudeepkumar staff 5.4M Nov 1 23:07 big-image.jpg
➜ ipfs add big-image.jpg
added QmYGKycApRjJ2sCUbj1czXBDKcrM5G4AaK3RrdDJ9CFKqa big-image.jpg
➜ ipfs add --chunker=size-1024 big-image.jpg
added QmcPGhUdyUy18QVnG5Sg2U3W4KcQahBg7PKXFXrYbcN6Y3 big-image.jpg
Out of the parameters that control the merkle DAG thus generated, chunker-size is one of them. It determines the size of leaf nodes that hold raw chunked data. As it turns out, pinata uses the default ipfs add parameters when adding/pinning content in its IPFS nodes (which is around 256kb); whereas web3.storage uses a chunk size of 1MB. This leads to different merkle trees and hence different CIDs.
This wouldn't work for us - we needed the operators to report the same CID (for same content) no matter what pinning service was used (for consensus purposes). Furthermore, if the DAG creation algorithm changed in the future, that would break things too. We need to keep CID calculation deterministic throughout the network's development.
Solution
IPFS provided content archives (CAR), which is a way to serialize the merkle DAG into a file and add that to IPFS. The generated merkle DAG is now part of the content uploaded, and the merkle DAG structure parameters can be kept consistent across all operator nodes (and independent of the pinning service used).
➜ ipfs add --chunker=size-262144 --raw-leaves big-image.jpg
added QmSQbRU4rCygu2XGC6DjVbBnpPJMz78z4Z5rTLz6gtrTWi big-image.jpg
➜ ipfs dag export QmSQbRU4rCygu2XGC6DjVbBnpPJMz78z4Z5rTLz6gtrTWi > carred.car
0s 5.39 MiB / ? [-------------------=-----------------------------------] 59.29 MiB/s 0s
The generated .car file is then uploaded to the pinning services, which have special handling for .car files, using the serialized merkle DAGs in them to figure out the CID, rather than recomputing it.
For my job, I used go-ipfs as a library to encapsulate all of this extra detail of adding/pinning content
Conclusion
CIDs are therefore not entirely self-describing content identifiers of data, and there are limits to them. You can think of content archives as more self-describing constructs than content identifiers.
Self-describing IPFS content identifiers and their limits
2022 Nov 01 See all postsThe vision and capabilities of IPFS have, to say the least, blown me away. A peer-hosted decentralized storage layer is something that captures the attention of idealists all around. So, it was exciting when I got the opportunity to hack on the kubo library, which is the golang implementation of IPFS.
The Problem
At CovalentHQ we extract, process, and index blockchain data to expose it as a unified API. The centralized version of this is already available, and we're currently creating a decentralized network which can do the same thing. This network will manufacture several network artifacts (e.g. block specimens) which need to be stored somewhere. One option for storage is AWS S3, or a self-hosted database layer. But what's the point of a decentralized network if the storage layer itself is centralized? Due to being decentralized and battle-tested, we chose IPFS to build our storage layer on.
Content Identifiers
In IPFS, you can "add" content, on which IPFS returns an identifier called content identifier or CID1. Now, CID is a self-describing format, which means a CID contains, within itself, the algorithms applied to the content to arrive at that particular CID. In other words, the CID encapsulates sufficient information within itself to figure out the hash which represents the content passed by the user.
Merkle DAGs
When you "add" content to IPFS, IPFS would split that into various "chunks" which are then laid out in a merkle DAG structure, the root of which is THE content identifier. Splitting the data into chunks allows reusability and better distribution of the data, which because crucial as the content size grows.
Pinning Services
Pinning services are hosted services that allow you to "pin" content to IFPS (which means the pinned content won't be GC'ed and deleted from the IPFS node). It ensures data persistence and availability which is needed whether we use pinning services like pinata, or have the network self-host the data (via IPFS). These pinning services essentially use IPFS nodes behind-the-scenes, served through web-apps and APIs.
Now, you would imagine that when we pin the data in any pinning service, the CID generated should be the same. But alas! That wasn't the case for web3.storage and pinata, each of which generated different CIDs.
Why was that?
Well, the CID ultimately generated depends on the algorithm used (and encoded) within the CID, yes. But it also depends on the structure of merkle DAG generated.
Out of the parameters that control the merkle DAG thus generated,
chunker-sizeis one of them. It determines the size of leaf nodes that hold raw chunked data. As it turns out, pinata uses the defaultipfs addparameters when adding/pinning content in its IPFS nodes (which is around 256kb); whereas web3.storage uses a chunk size of 1MB. This leads to different merkle trees and hence different CIDs.This wouldn't work for us - we needed the operators to report the same CID (for same content) no matter what pinning service was used (for consensus purposes). Furthermore, if the DAG creation algorithm changed in the future, that would break things too. We need to keep CID calculation deterministic throughout the network's development.
Solution
IPFS provided content archives (CAR), which is a way to serialize the merkle DAG into a file and add that to IPFS. The generated merkle DAG is now part of the content uploaded, and the merkle DAG structure parameters can be kept consistent across all operator nodes (and independent of the pinning service used).
The generated .car file is then uploaded to the pinning services, which have special handling for .car files, using the serialized merkle DAGs in them to figure out the CID, rather than recomputing it.
For my job, I used go-ipfs as a library to encapsulate all of this extra detail of adding/pinning content
Conclusion
CIDs are therefore not entirely self-describing content identifiers of data, and there are limits to them. You can think of content archives as more self-describing constructs than content identifiers.
proto.school tutorial↩︎